We have developed a first draft of the software to do automatic segmentation
of the USFS images. Previously we created a database of forestry images
manually segmented into six typical regions (tree, foliage, bush, grass,
sky and background sky). Here are the definitions
of each of these regions. With this database, we estimate models specific
to each region using the segmentation software. These models can then be used
to automatically segment images on a block-by-block basis. This page documents
our preliminary experiments on this automatic segmentation task.
Performance:
We evaluated the system with three different feature sets on data set 1 of
the Pre-Phase 01 images. The best segmentation results we achieve is a 61.4%
block classification error rate by using blue + brown as the feature set.
We also investigated the effect of the window size on classification rate.
Here are detailed results.
Analysis:
We carefully analyzed the confusion matrices from the above experiments.
We notice that a significant portion of the errors occur with the foliage
blocks. Currently, for each specific region, the errors made by the best
system can be classified as: tree - 47.3%, foliage - 86.1%, bush - 44.1%,
grass - 52.9%, background sky - 26.6%, sky - 10.0%. Obviously, a better
foliage classifier will be the key to the improvement of the system.
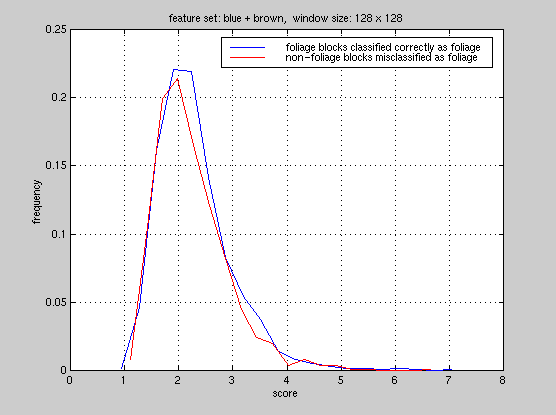
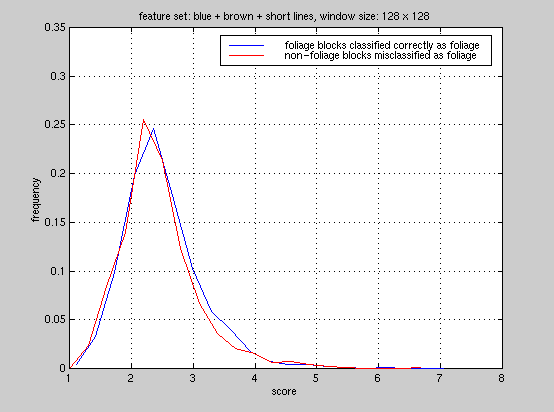
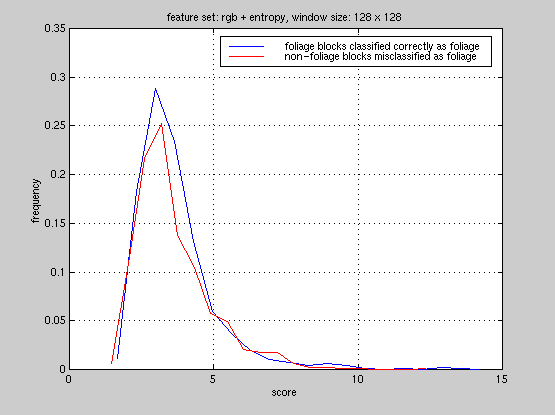
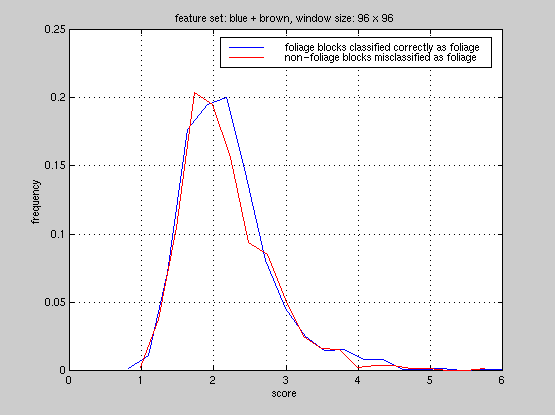
To this end, we studied the foliage classifier from a statistical viewpoint.
In our PCA system, we compute distances of a test feature vector from all
the reference vectors and assign the block a label corresponding to the
reference it is closest to. We computed the distribution of scores the
foliage classifier generated in each experiment, false-alarms and accuracy.
Here are the plots for experiment
#1, #2,
#3, and
#4.
From these plots, it is clear that the foliage classifier we used in these
experiments is not able to discriminate foliage blocks and non-foliage
blocks. Currently, we are computing all 65 features on the foliage regions
and studying their statistical characters. We would like to choose those
significant features for the foliage classifier that can help better
discrimination. If PCA can not succeed in this, we will try better techniques
such as Linear Discriminant Analysis (LDA). From the results we also notice
that the window size does not have a significant bearing on the classification
rate.
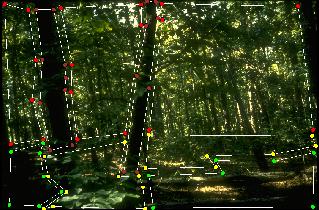
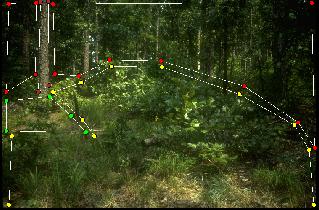
Example Segmentation Results:
Some segmentation results are shown in the table below. We got these results
from experiment #1. Here, we use different
colors for different regions. The mapping relationship is
- brown - tree
- red - foliage
- yellow - bush
- green - grass
- light blue - background sky
- dark blue - sky
{kind=link}
{kind=link}
{kind=link}
{kind=link}