Goal
Our goal is to assess baseline performance of deep learning systems on operational banking data provided by the U.S. Federal Government (FDIC). Operational data contain many forms of imperfection that make it extremely difficult for the application of traditional deep leaning systems. Given a consistent number of reporting periods, we aim to predict if a bank will fail before the end of the next quarter, only considering the fixed effects of the data from the bank rather than random effects of exogenous variables.
Downloadable Content
The data and software used in this publication:
Jungreis, D., & Picone, J. (2019). Predicting Endogenous Bank Health from FDIC Statistics on Depository Institutions Using Deep Learning. In Proceedings of Computing Conference (pp. 1–9). London, UK.
can be downloaded here. Further questions regarding the Predicting Bank Health project or the downloads within this project should be sent to Dave Jungreis.
Synopsis
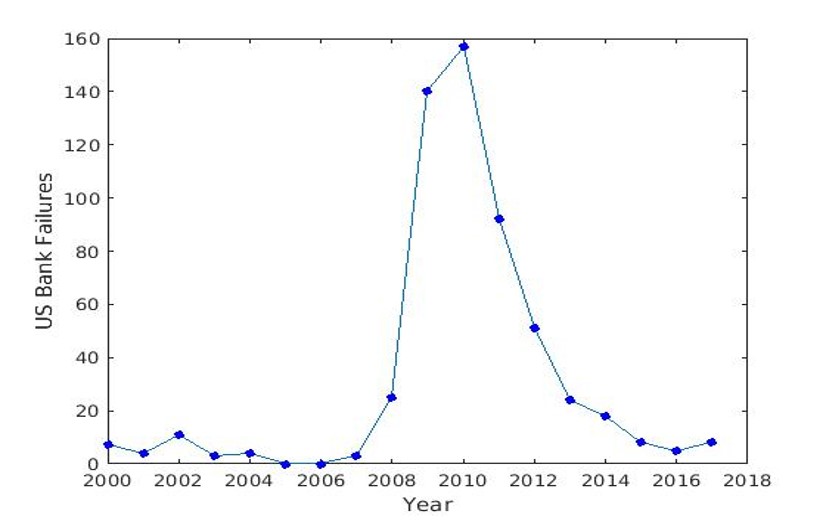
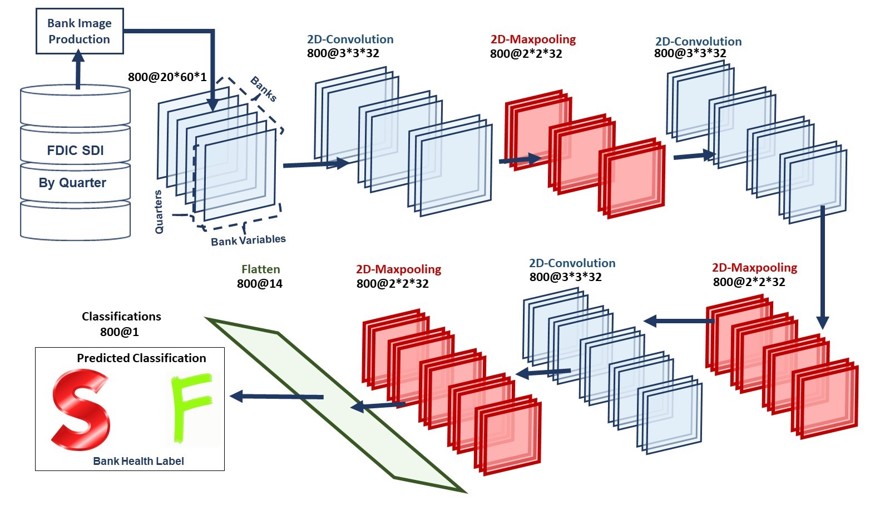
The Federal Deposit Insurance Corporation (FDIC) keeps records of banking data in its Statistics on Depository Institutions (SDI) going back to the fourth quarter of 1992. The data are reported quarterly on approximately 1,050 variables, such as total assets, liabilities, and deposits. We hypothesized that impending failure could be predicted from these data. We restricted the database to 60 quantitative variables that had no missing data for any bank in any quarter during the epoch under consideration: the first quarter of 2000 through the second quarter of 2017. Deep learning approaches based on multilayer perceptrons and convolutional neural networks were evaluated and failed to accurately predict failures better than guessing based on priors. These baseline experiments, particularly the inability to overfit to the training data, show the challenges of finding failure-predicting trends that are strictly intrinsic to a bank. Future deep learning work would have to include exogenous factors to link quarterly observations between banks.
Baseline System
US Bank Failures