|
A speech recognition system is an integration of knowledge across several domains such as digital signal processing, natural language processing and machine learning. With the evolution of technology, and the ever- increasing complexity of speech recognition tasks, the development of a state-of-the-art speech recognition system becomes a time-consuming and infrastructure-intensive task. Since 1998, we have focused on the development of a modular and flexible recognition research environment which we refer to as the production system. The toolkit contains many common features found in modern speech to text (STT) systems: a front end that converts the signal to a sequence of feature vectors, an HMM-based acoustic model trainer, and a time-synchronous hierarchical Viterbi decoder. In the following sections, I will describe how these major components are designed in our toolkit so that it brings you competitive technology with maximum flexibility. Front End Builder An acoustic front end refers to the portion of the recognition system that extracts feature vectors from the speech data. The development of a completely new front end is a software intensive task. The re-implementation of existing algorithms from scratch has slowed down many researchers' efforts. The goal of our front end builder is to provide users an efficient environment for the evaluation of new research ideas. The design of this tool included these requirements:
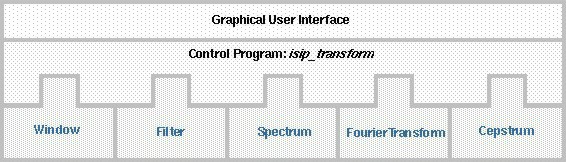
The front end builder is designed as a three-level structure (shown in figure above) so that above requirements can be achieved. First of all, at the lowest level, a number of core DSP algorithms are implemented as C++ classes, providing high computational efficiency. These algorithms include different types of windows, filters, filter banks, etc. All the algorithms share a common virtual function interface known as an interface contract. Users can plug in their own algorithms into the front end builder by following the predefined interface specification, without a need to write any new GUI code. Similarly, new algorithm classes can be added to the algorithm library without changing any of the existing code base. A Java GUI tool was developed to provide users a block diagram approach to designing acoustic front ends. When building a new front end, a user can select from a library of existing algorithms, and can configure all parameters associated with these algorithms from the tool. The Java language was used so that the tool can run across a wide range of platforms (including Microsoft Windows), and in order that the tool could be built using an industry-standard look and feel. The output of the GUI tool is a recipe that schedules the sequences of required signal processing operations. A control program was developed to process the configuration file, pass data through algorithms and generate the final feature vectors. We have successfully built several complex front ends with this tool, including an industry standard front end based on Mel-frequency cepstrum coefficients (MFCCs). The control program supports multi-pass processing, which allows non-real-time research ideas involving complex normalization and adaptation schemes to be easily implemented. Hierarchical Decoder Time-synchronous Viterbi beam search has been the dominant search strategy for continuous speech recognition systems for the past 20 years. Search is a good example of an algorithm that is conceptually simple, but extremely hard to implement in a general way in practice. Worse yet, the slightest inefficiencies in search can result in a system that cannot solve large-scale problems. Most search implementations are restricted to one approach (e.g., time-synchronous Viterbi search) and cannot be separated from the statistical modeling approach (e.g., HMM). Further, the search structure is limited to three levels (e.g., word, phone, and state).The goals for the design of our generalized decoder were:
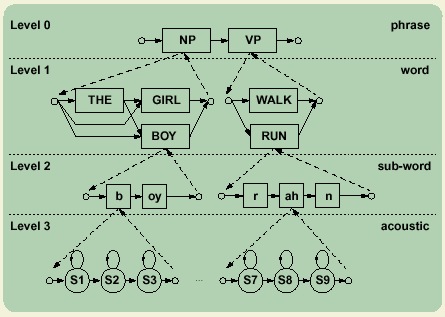
These goals are achieved by the abstraction of the generalized hierarchical search space, shown in the figure above. In such a search space, each level can be conceptually considered as the same. Phrases, words or phones are simply symbols at different levels. Each level contains a list of symbols Sij and a list of graphs Gik., where, i is the index of the level, j is the index of the symbol and k is the index of the graph. Each graph has at least two dummy vertices, the start vertex and the terminal vertex both indicating the start and the end points of the graph in a search space. The lower level graph (such as the graph with WALK and RUN) is the expansion of the symbol (such as the symbol with VP) at the level above. This relationship connects all the levels together, realizing the entire search space. There are two exceptions for such a symbol-graph expansion. First, at the highest level, only one graph can exist. This graph is called the master grammar. It is a map for the decoder to iterate through the entire search space. Second, at the lowest level, each symbol represents an underlying statistical model. These symbols can not be expanded into a sub-graph. Observations probabilities will be evaluated when the search process reaches these symbols. Acoustic Trainer Our acoustic trainer is a supervised learning machine that estimates the parameters of the acoustic models given the speech data and transcriptions.In most HMM-based systems, a phonetic transcription is required as input to the parameter reestimation process. This transcription is derived at automatically and iterated upon as the recognition system improves. Silence must also be hypothesized between each word model, since we don't know where in the utterance silence actually occurred. In essence, the trainer decides on the optimal alignment of the hypothesized transcription as part of the training process. 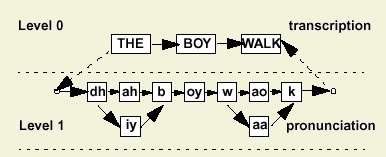
The trainer we implemented is based on a hierarchical search space described in the previous section. It imposes no constraints on the topology of any model in the hierarchical structure. With such a flexible design, our network trainer, which is depicted in the figure above, alleviates the need for a phonetic transcription. Instead, it is capable of hypothesizing all possible expansions of a symbol list, and performing parameter re-estimation across this expanded network. The benefits are twofold: we remove the dependency on an intermediate transcription, and we can inherently train statistical pronunciation models. This data-driven approach often results in better performance. Programming Interfaces All the utilities presented above were developed based on an extensive set of foundation classes (IFCs). IFCs are a set of C++ classes organized as libraries in a hierarchical structure. These classes are targeted for the needs of rapid prototyping and lightweight programming without sacrificing the efficiency. Some key features include:
Future Work Our future work will follow two directions: (1) the development of core algorithms to improve recognition accuracy and speed, and (2) integration of natural language processing and dialogue modeling tools. Over the next year, we will release our first real-time dialogue systems application as well as many improvements to the core speech recognition system. The complete software toolkit release is available on-line at http://www.cavs.msstate.ed./projects/speech/index.html. |