 |
|
|
|
|
|
|
|
|
|
 |
|
|
|
 |
|
|
|
|
|
| • |
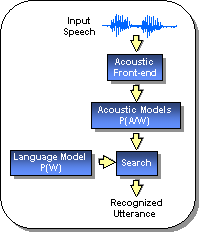
The
signal is converted to a sequence of
|
feature vectors based on spectral and
|
|
temporal measurements.
|
|
|
|
|
|
|
|
|
|
|
|
|
| • |
Acoustic
models represent sub-word
|
units, such as phonemes, as a finite-
|
|
state machine in which states model
|
|
|
spectral structure and transitions
|
|
model temporal structure.
|
|
|
|
|
|
|
|
|
|
|
|
| • |
The
language model predicts the next
|
|
set
of words, and controls which models
|
|
are hypothesized.
|
|
|
|
|
|
|
|
|
|
|
|
|
| • |
Search
is crucial to the system, since
|
|
many
combinations of words must be
|
|
|
investigated
to find the most probable
|
word
sequence.
|
|
|
|
|
|
|