Alphadigits
The
CSLU Alphadigit Corpus
(AD) is a collection of about 78,000 examples from
3,031 talkers saying strings of letters and digits over the
telephone. The data was recorded directly off of a digital T1 phone
line without digital-to-analog or analog-to-digital conversion at the
recording end. An 8kHz sampling rate was used. The data is available
from the
Center for Spoken Language Processing
at the
Oregon Graduate Institute.
|

"7,W,P,P"
|
CALLHOME Mandarin Chinese Speech
The CALLHOME Mandarin Chinese corpus of telephone speech consists of 120
unscripted telephone conversations between native speakers of
Mandarin Chinese.
All calls, which lasted up to 30 minutes, originated in North America and
were placed to locations overseas.
The data can be found
here
at the
Linguistic Data Consortium.
|
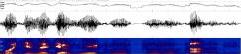
""
|
CALLHOME American English Lexicon (PRONLEX)
The CALLHOME American English Lexicon was originally distributed under the name
COMLEX Pronouncing Lexicon, or PRONLEX.
The latest version of PRONLEX contains 90,988 lexical entries and includes
coverage of WSJ30, WSJ64, Switchboard and CallHome English.
This data can be found
here
at the
Linguistic Data Consortium.
|

"Lexicon "
|
CMU Kids Corpus
This database is comprised of sentences read aloud by children. It was
originally designed in order to create a training set of children's speech for
the SPHINX II automatic speech recognizer for its use in the LISTEN project at
Carnegie Mellon University.
This data can be found
here.
|

"The storms have big winds. "
|
ICSI STP Hybrid Switchboard Corpus
The ICSI Switchboard Transcription Project used a hybrid symbol set, composed
of phonetic symbols derived from the TIMIT corpus, along with diacritical
elements to show deviation from canonical patterns.
Transcribers then corrected both the phone labels and phone alignments.
This data can be found
here
at the
International Computer Science Institute.
|

"We put too much uh responsibility on the teachers
for things that are really not education they're
social services."
|
JEIDA
The Japan Electronic Industry Development Association's Common
Speech Data (JCSD) Corpus is an isolated phrase corpus consisting of
150 speakers (75 males/75 females) and almost 200,000 utterances.
This data can be found
here
at the
Linguistic Data Consortium.
|

" "
|
Penn Treebank
The Penn Treebank Project annotates naturally occurring text for linguistic
structure. Also there are skeletal parses showing rough syntactic and semantic
information with annotated text with part of speech tags,
and for the Switchboard corpus of telephone
conversations and dysfluency annotation.
This data can be found
here
at the
Department of Computer and Information Science
at the University of Pennsylvania.
|

"Well Kathleen do you believe that there is a
problem with our public school system "
|
Resource Management
The Resource Management corpus consists of prompted queries in very low
background noise conditions. The prompts were chosen from a
limited grammar. Recording was carried out using a headset microphone
and simultaneously digitized at 20 kHz. Each recording session was
then downsampled to 16 kHz. The Resource Management corpus can be purchased
here.
|

"List locations and speeds for submarines that are in West Persian sea."
|
SPINE Evaluation Audio Corpus
The Speech in Noisy Environments (SPINE) Evaluation Audio Corpus,
created for the
Department of Defense Digital Voice Processing Consortium.
There are a total of 120 files, one conversation each, for a rough total of
9 hours and 22 minutes (2.2 Gigabytes) of audio data.
This data can be found
here
at the Linguistic Data Consortium.
|

"Charlie mayday ok. "
|
SPINE2 Evaluation Audio Corpus
This corpus was used as part of the training set for the Second Speech in
Noisy Environments Evaluation. SPINE2 provides a continuing forum
for assessing the state of the art and practice in speech recognition
technology for noisy military environments and for exchanging information on
innovative speech recognition technology in the context of fully implemented
systems that perform realistic tasks.
This data can be found
here
at the
Linguistic Data Consortium.
|
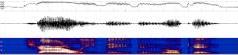
"Ah, good we sunk the ship. "
|
Switchboard
The Switchboard corpus consists of spontaneous conversations averaging
6 minutes in length. Over 500 speakers of both sexes from every major
dialect of American English are represented. The data is a digital
version of speech signals collected directly from the telephone network
over T1 lines by automatic switching software.
|

"What are your m[ain] music interests? "
|
TIDigits
The TIDigits corpus consists of more than 25 thousand digit sequences
spoken by over 300 men, women, and children. The data was collected in a
quiet studio environment and digitized at 20 kHz. However, most experiments
begin by downsampling the data to 8 kHz. TIDigits can be purchased
here.
|

"2,0,1,1,6"
|
Wall Street Journal (WSJ0)
The WSJ database was generated from a machine-readable corpus of Wall Street
Journal news text.
Some spontaneous dictation is included in addition to the read
speech. The dictation portion was collected using journalists who dictated
hypothetical news articles.
This data can be found
here
at the
Linguistic Data Consortium.
|
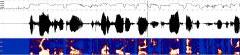
"The sell of the hotels is part of holiday strategy
to sell off assets and concentrate on property
management. "
|