|
4.2.2 Network Decoding:
Recognition Using Word Models In this section, we will focus on speech recognition using word models. Word models are one of many different types of acoustic models that can be used in our recognition system. We will use the recognizer to decode a list of test utterances and will briefly explain the recognition process. Let's start by decoding a list of test utterances. We'll use utterances from the TIDIGITS subset introduced in Section 2. The features for this subset have already been extracted. Go to the directory $ISIP_TUTORIAL/sections/s04/s04_02_p02/.
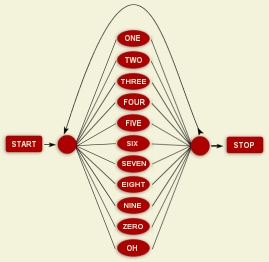
Command: isip_recognize -parameter_file params_decode.sof -list /ftp/pu./projects/speech/software/tutorials/production/The console output provides some brief diagnostic information about the results, including the hypothesis for the current utterance, and the (log) likelihood that the hypothesis is correct. (Technically, this is simply a score presented on a log scale that reflects the similarity between the utterances and the best sequence of models that could have produced this score.) Now, let's briefly examine the components needed to complete the recognition process. There are two console input files, a parameter file and a list of audio utterance identifiers. The first input, a parameter file, is explained in detail in Section 4.2.6. The second item is described in detail in Section 2.4.2. It simply defines a list of utterances to be processed using utterances identifiers. The parameter file's main purpose is to provide a reference to the three main components of the recognizer: a front end, an acoustic model library, and a hierarchy of language models. You can view the parameter file, params_decode.sof, in your browser. It contains the following information: @ Sof v1.0 @ @ HiddenMarkovModel 0 @ algorithm = "DECODE"; implementation = "VITERBI"; output_mode = "DATABASE"; output_type = "TEXT"; output_file = "$ISIP_TUTORIAL/sections/s04/s04_02_p02/results.out"; frontend = "$ISIP_TUTORIAL/recipes/frontend.sof"; audio_database = "$ISIP_TUTORIAL/databases/db/tidigits_audio_db_test.sof"; language_model= "$ISIP_TUTORIAL/models/word_models/compare/lm_word_jsgf_8mix.sof"; statistical_model_pool = "$ISIP_TUTORIAL/models/word_models/compare/smp_word_8mix.sof";This is a text Sof file that contains the essential files to configure and run the recognizer. Algorithm and implementation specify recognition mode (e.g., DECODE), and the type of search algorithm to be used (e.g., VITERBI). The parameters output_file and output_type direct the recognizer to store the results in text format in the file "results.out". The default output format is binary, which is necessary for large-scale experiments. However, we use text mode so we can easily view the results. The parameter frontend specifies the front end used to convert audio data to features. This process is discussed extensively in Section 3. The recognizer needs this input file so that it can check whether the front end used to generate the acoustic models is compatible with the front end used to generate the features. The parameter audio_database specifies the audio database to be used to reference the input list, identifiers_test.sof, which contains identifiers, to the correct audio data. Each identifier corresponds to a record in the audio database that provides an audio data file name (in this case a feature file). There is a corresponding entry in the transcription database, which is not used here, that can contain a start and stop time in the audio file that defines the utterance to be processed. This is described in more detail in Section 2.4.2. The language model file specifies a hierarchy of language models that include a word-level grammar, which controls what sequences of words are allowed, and a mapping of words to acoustic models. This component of the system actually merges acoustic and language modeling into a hierarchy of finite state machines. Acoustic modeling is described in more detail in Section 5; language modeling is described in more detail Section 6. The final parameter, statistical_model_pool, describes a set of statistical models, typically Gaussian mixture models, which represent the terminal nodes in the hierarchy language models, and allow feature vectors to be converted to likelihoods.
Once the results have been acquired by the recognizer, a scoring report can be produced. Scoring is the process of comparing the results from the recognizer to a true transcription of the utterances. The scoring report contains a lot of useful information and statistics. Scoring is explained in detail in Section 4.3. |
||||||