4.2.3 Network Decoding:
Recognition Using Context-Independent Phones

This section focuses on another type of acoustic model called a
context-independent phone model.
Phone models,
unlike word models, do not model the words themselves. Instead, they
model small units of the word.
Again, we will start by decoding a single utterance. We will use the same
utterance from the previous section. The language and acoustic models we
will use, however, are different. The new language and acoustic
models are for recognizing speech using phone models instead of word
models. Go to the directory $ISIP_TUTORIAL/sections/s04/s04_02_p03/.
cd $ISIP_TUTORIAL/sections/s04/s04_02_p03/
and run the following command:
isip_recognize -parameter_file params_decode.sof -list $ISIP_TUTORIA./databases/lists/identifiers_test.sof -verbose ALL
This will produce the following output:
Command: isip_recognize -parameter_file params_decode.sof -list /ftp/pu./projects/speech/software/tutorials/production/
fundamentals/current/example./databases/lists/identifiers_test.sof -verbose ALL
Version: 1.23 (not released) 2003/05/21 23:10:45
loading audio database: $ISIP_TUTORIA./databases/db/tidigits_audio_db_test.sof
*** no symbol graph database file was specified ***
*** no transcription database file was specified ***
loading front-end: $ISIP_TUTORIAL/recipes/frontend.sof
loading language model: $ISIP_TUTORIAL/models/ci_phone_models/compare/lm_phone_jsgf_8mix.sof
loading statistical model pool: $ISIP_TUTORIAL/models/ci_phone_models/compare/smp_phone_8mix.sof
*** no configuration file was specified ***
opening the output file: $ISIP_TUTORIAL/sections/s04/s04_02_p03/results.out
processing file 1 (ah_111a): $ISIP_TUTORIA./databases/sof_8k/test/ah_111a.sof
hyp: ONE ONE ONE
score: -9122.6484375 frames: 138
processing file 2 (ah_1a): $ISIP_TUTORIA./databases/sof_8k/test/ah_1a.sof
hyp: ONE
score: -5187.28173828125 frames: 79
.....
Again, the output indicates that the files were processed successfully. It's
important to remember that although the file was processed correctly,
the output may not be the correct utterance. The score value indicates
how likely the output utterance is a correct transcription of the spoken
utterance. The lower the value, the lower the likelihood. Compare your
results with the file
results.out.
Let us examine the parameter file in more detail. You can
view the parameter file,
params_decode.sof,
in your browser. It contains the following information:
@ Sof v1.0 @
@ HiddenMarkovModel 0 @
algorithm = "DECODE";
implementation = "VITERBI";
output_mode = "DATABASE";
output_type = "TEXT";
output_file = "$ISIP_TUTORIAL/sections/s04/s04_02_p03/results.out";
frontend = "$ISIP_TUTORIAL/recipes/frontend.sof";
audio_database = "$ISIP_TUTORIA./databases/db/tidigits_audio_db_test.sof";
language_model= "$ISIP_TUTORIAL/models/ci_phone_models/compare/lm_phone_jsgf_8mi
x.sof";
statistical_model_pool = "$ISIP_TUTORIAL/models/ci_phone_models/compare/smp_phon
e_8mix.sof";
This contents of this file are explained in
Section 4.2.2.
As mentioned previously, phones denote the minimal acoustic units
of speech, specific to a language, that enable humans to distinguish
between words. The phones can
be recognized and combined to form words using a process called
word-to-phones mapping. These maps are collectively
known as the
lexicon.
The lexicon describes the pronunciations of all the words in the
vocabulary by mapping groups of phones to the matching word. The
lexicon can either be represented linearly or as a graph. Graph
representations are generally used when words have multiple
pronunciations. For example, in TIDigits, the word zero can be
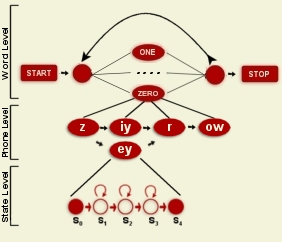
pronoucend with the phones "z iy r ow" or "z ey r ow"(See the
phone level in the figure to the right.)
TIDigits has a vocabulary of 11 words.
Phone models are necessary when implementing large
vocabulary speech recognition (LVCSR) systems. An LVRS system in
English may include over 70,000 words.
Since all of these words can be recognized using only 46 possible phones
versus 70,000 different word models, LVCSR systems typically use phone
models. Also, phone models are shorter than word models and require
significantly less parameters. The use of phone models adds another
level, the phone level, to the recognition
process. (See the figure to the right.)
Not only does the recognizer have to recognize the individual
phones, but it must combine these phones using word-to-phones mapping.
|
|
How does the language model file change when using phone models? As
mentioned previously, the use of phone models adds another level to the
recognition
process. This new level must be defined in the language model. Recall
that in a recognition system using word models, the pronunciation of
the word is simply the word itself. In other words, the phone level
can be replaced by a dummy level or omitted. If a dummy level is used,
the word is described as a single phone which is the word itself. (Hence
the name 'dummy level'.) When using phone models, however, this level
requires a much more complex definition. Each phone is defined and
mapped to its corresponding states. This is the connection from phone
level to the state level. Each word in the word level must also be
mapped to its corresponding phones, thus connecting it to the phone
level. The image above illustrates this with lines between each level.
The term context-independent means that the recognition of a certain
phone does not depend on the phone's preceding or following phones.
Context-dependent phones consider the preceding and following phones in
the recognition process.
This type of acoustic model
in explained in detail in the next section
(Section 4.2.4).
|
|







